Published
- 7 min read
The Shape of Blue: Measuring How Language Bends Meaning
Jakob von Uexküll’s most famous creature is the tick.
In the vast chaos of a forest — millions of scents, sounds, textures, movements — the tick’s lived world collapses into a tiny handful of cues: climb toward light, detect butyric acid, find warmth, seek skin. Out of everything that exists, only a few signals become real for that organism. Uexküll called this selective slice of reality the creature’s Umwelt — its experienced, action-relevant world.
Here’s the uncomfortable extension: humans have Umwelten too.
We don’t live in raw reality. We live in world-models — structured by perception, memory, culture, and crucially, by language. And those world-models aren’t just different in content (“you have a word for that; I don’t”). They might be different in shape.
That’s the hypothesis I’ve been testing. And the results are strange enough to be worth sharing.
The Russian Blues Problem
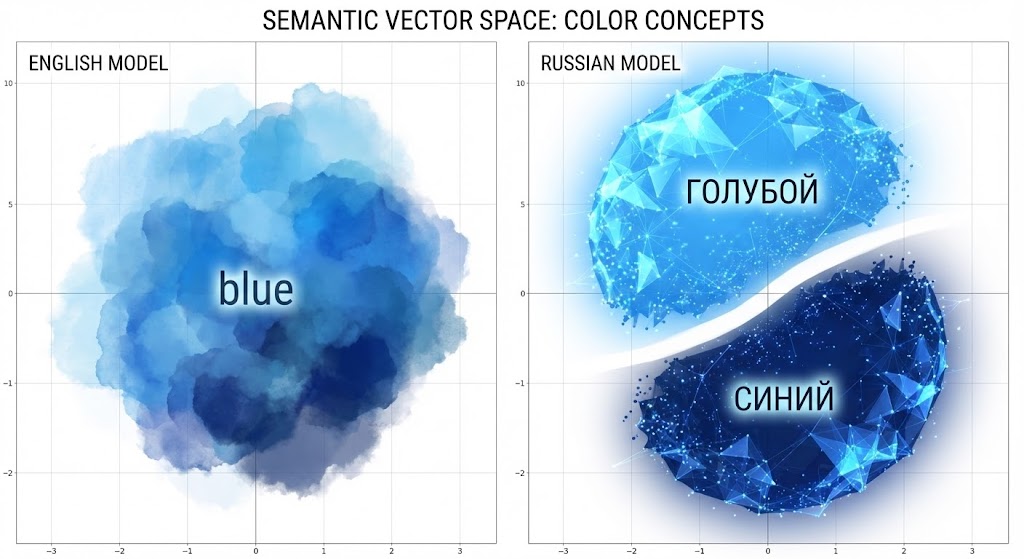
In 1969, two anthropologists named Brent Berlin and Paul Kay published a book arguing that color terms across languages follow universal patterns. The claim sparked decades of debate, but one finding kept surfacing that didn’t fit the tidy universalist story: Russian blues.
English has one basic word for blue. Russian has two: goluboy (голубой) for lighter blues — sky, cornflowers, a clear winter morning — and siniy (синий) for darker blues — navy, deep water, twilight.
This isn’t just vocabulary trivia. In 2007, researchers showed that Russian speakers can discriminate between shades of blue faster when those shades cross the goluboy/siniy boundary — but only when they’re using their language-processing faculties. Block their verbal working memory with a distractor task, and the advantage disappears.
The implication is unsettling if you think about it: the word carves a groove in perception. The boundary between “light blue” and “dark blue” becomes more real — more cognitively salient — because the language marks it.
But here’s what’s been missing: we’ve had behavioral evidence (reaction times, discrimination thresholds) without any way to look at the structure of the representations themselves. We knew language was doing something, but we couldn’t see what shape that something had.
Until now, maybe.
Using Language Models as Microscopes
Large language models like GPT and Llama aren’t thinking machines. They’re something arguably more useful for science: they’re massive compression artifacts of human linguistic patterns.
When a model like Llama processes the word “blue,” it doesn’t just retrieve a dictionary definition. It activates a pattern across thousands of dimensions — a point in a vast geometric space where similar meanings cluster nearby. These embedding spaces are learned entirely from human text. They’re distillations of how humans actually use words.
Which makes them, potentially, instruments for studying the geometry of human meaning.
The hypothesis I’ve been testing — I call it the Geometric Whorfian Hypothesis — is that different languages don’t just label a shared conceptual space differently. They warp that space. The distances between meanings, the boundaries between categories, the “shape” of a concept — these might actually differ across languages in measurable ways.
And the Russian blues are the perfect test case.
What We Found
We fed Russian and English color terms into a large language model (Llama 3.1) and extracted the geometric representations at each layer of the network. Then we asked a simple question: does the space of Russian blue terms show a categorical split that English lacks?
The answer was yes — clearly and consistently.
In Russian, the terms fell into two distinct families: goluboy-family (light blues) on one side, siniy-family (dark blues) on the other. The boundary was sharp. When we measured whether you could draw a line perfectly separating the two categories across the model’s 32 layers, we got 80% perfect separation — 26 out of 32 layers showed a clean categorical boundary.
English? 40%. The “light blue” and “dark blue” terms cluster somewhat, but the boundary is fuzzy, graded, uncertain.
This isn’t subtle. The Russian space is organized differently.
Here’s the part that surprised us: the Russian compound term svetlo-siniy (literally “light-siniy” — what you might translate as “light dark-blue”) clusters with the siniy family, not with goluboy. In English, “light blue” might seem closer to “sky blue.” But the Russian morphology wins: if it’s built on the siniy root, it lives in siniy territory.
The categorical structure isn’t imposed by translation equivalence or surface similarity. It reflects the internal logic of the language itself.
The Deeper Geometry
There’s a wrinkle that makes this more interesting.
At layer 31 — nearly the final layer of the network — something happens. The clean categorical boundary that held for most of the model’s depth suddenly breaks down. English and Russian start behaving more similarly, the structure getting fuzzier.
Why? We’re not certain yet. One possibility: the final layers are increasingly optimized for the model’s actual output task (next-word prediction in English). The deeper linguistic structure — the categorical geometry that different languages carved during earlier processing — gets smoothed out as the model prepares to generate text.
If that’s right, it suggests that the interesting cognitive structure isn’t at the “output” level of language processing. It’s in the middle layers — the place where meaning is being actively organized before it gets squeezed back into words.
What This Might Mean
I want to be careful here. We’re measuring geometry in a language model’s representations, not directly in human brains. The model learned from human text, so there’s reason to think it’s capturing something real about human semantic organization — but the link isn’t proven.
Still, if these findings hold up, they suggest something profound:
Language doesn’t just label pre-existing categories. It creates the categories.
Not arbitrarily — the world still pushes back. You can’t have a language where “blue” means “heavy” and “green” means “Tuesday.” But within the space of physically possible perceptions, languages draw boundaries, and those boundaries become cognitively real. The geometry of meaning — which concepts are “close” to each other, which boundaries are “sharp” — is partially constituted by the language you speak.
This isn’t linguistic determinism. Russian speakers aren’t trapped in a two-blue world any more than English speakers are trapped in a one-blue world. But the default organization, the path of least resistance, the shape that meaning takes when you’re not actively fighting it — that’s different.
What Comes Next
This is one study, in one domain (color), with one model architecture. The real test is whether the pattern generalizes:
- Other languages: Greek has a similar two-blues distinction. Hungarian carves up red more finely than English. Vietnamese xanh covers both blue and green.
- Other domains: Does Russian’s richer vocabulary for types of motion create different geometric structure in action concepts?
- Other models: Do these patterns appear in models trained on different data, with different architectures?
- Behavioral validation: Do the geometric distances in the model predict human reaction times, similarity judgments, or memory errors?
We’re working on all of these.
Why It Matters
Partly this is just basic science: how does language relate to thought? It’s one of the oldest questions in cognitive science, and we now have new tools for asking it.
But there’s a practical angle too.
If AI systems trained on text inherit the geometric biases of their training languages, that matters for how they translate, reason, and communicate across linguistic communities. A system that “thinks” in English-shaped semantic space might systematically misunderstand concepts that are carved differently in other languages — not because of missing vocabulary, but because of mismatched geometry.
Understanding this wouldn’t just be interesting. It might be necessary for building AI that can actually bridge human conceptual worlds rather than flattening them.
The tick’s world is simple: a few chemical signals, a few behavioral responses, a complete Umwelt.
Ours is richer — but still bounded. We live in the semantic spaces our languages and cultures have carved for us, mostly without noticing the walls. The project of measuring those spaces, making the invisible geometry visible, feels like a small step toward seeing the shape of our own cage.
Or maybe, eventually, beyond it.
This post describes work in progress. I’m an independent researcher with a background in computational modeling of complex systems. The work uses language models as instruments for cognitive science — we’re studying what they reveal about human semantic organization, not making claims about machine consciousness or understanding. A paper on the Russian blues findings is currently under peer review.